
API Design Interview: A Complete Walkthrough (with a Real Meta Question)
A real Meta-style API design problem, solved end-to-end — resource modeling, pagination, idempotency, versioning, rate limits, and what each decision actually earns you on the rubric.

API design interviews are not system design interviews with smaller boxes. They’re their own thing, scored against their own rubric, and they reward a completely different set of instincts. System design rewards the architect who can decompose a problem into services and reason about scale. API design rewards the contract designer — the engineer who can take a business need and turn it into a surface that other engineers will be using, hating, or thanking you for, five years from now.
Most articles about API design interviews stop at the format. “You’ll be asked to design an API. Here are the categories of questions. Good luck.” Useful in 2018, useless in 2026. What you actually need is to watch a full question solved end-to-end, with someone telling you what each decision is earning you on the scorecard.
So let’s do that. We’re going to use a real Meta-style question, walk through it phase by phase, and at every decision point I’ll annotate what that move signals to the interviewer.
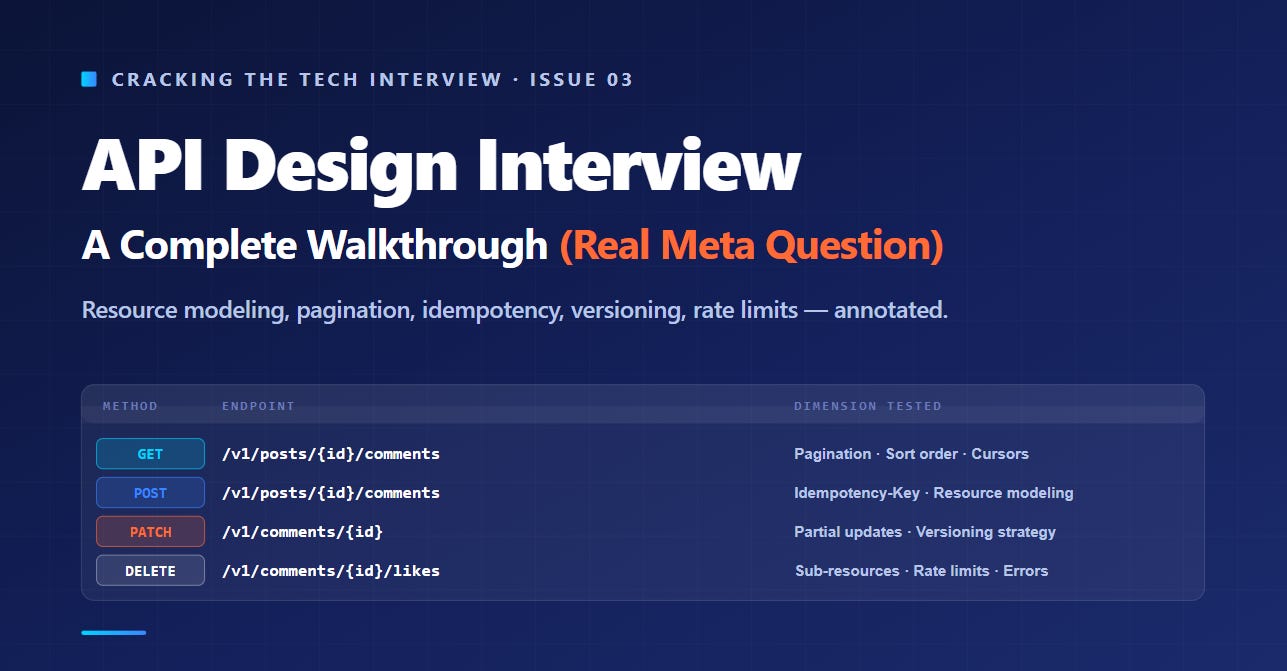
The question, as the interviewer reads it: “Design the public API for Instagram’s commenting system. Users should be able to leave comments on posts, see comments left by others, like comments, reply to comments, and delete their own comments. Walk me through the API surface.”
This is a great question because it looks deceptively simple. It’s “just CRUD on comments.” It is not. Inside this question are at least seven distinct API design dimensions — and the candidates who treat it as CRUD walk out with a no hire.
What’s actually being scored
Before we touch the question, here’s the rubric. API design interviews are graded on roughly seven dimensions, and you should know all of them by name:
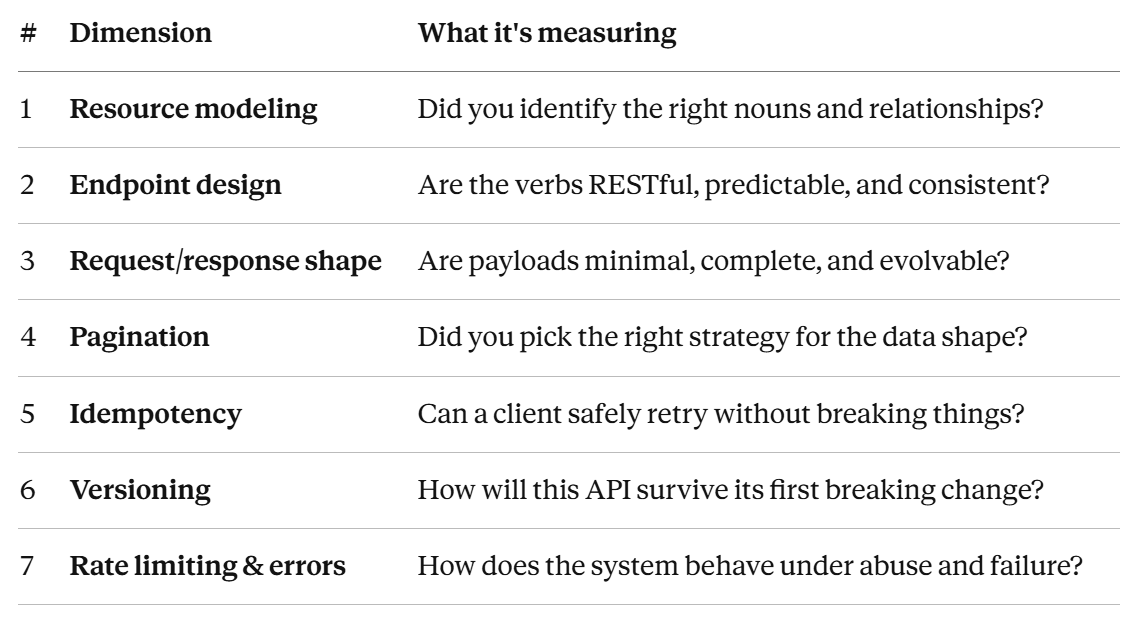
The unspoken eighth dimension — consistency of thought across all of the above — is what separates a 4 from a 5. We’ll come back to that at the end.
Phase 1 · Clarification (the part everyone skips)
Just like in coding interviews, the candidate who jumps straight to endpoints fails before they’ve drawn a single line. The first three minutes are about turning “design Instagram comments” into a buildable spec.
Here’s what a strong opening sounds like:
“Before I sketch anything, let me make sure I understand the scope. A few clarifying questions:
One — is this a public API meant for third-party developers, or an internal API meant for Instagram’s own clients (web, iOS, Android)? The answers diverge a lot. A public API needs more careful versioning, OAuth scopes, and rate limit tiers. An internal API can be more pragmatic.
Two — what’s the read-to-write ratio? Comments are extremely read-heavy on Instagram — a viral post might have a million reads for every write. That changes how I think about caching and pagination cursors.
Three — what comment features are in scope? Just text? Or also: mentions, hashtags, emoji reactions distinct from likes, threaded replies more than one level deep, edit history, pinned comments by the post author?
Four — what’s the abuse model? Comments are one of the most abused surfaces on any social platform. Are we designing rate limiting and moderation hooks into the API, or assuming a separate system handles that?
Five — soft delete or hard delete? When a user deletes their comment, does it disappear entirely, or do we keep a tombstone for moderation appeals and audit?”
The interviewer will typically answer: public-facing API, very read-heavy, text + mentions + one level of replies (no infinite threading), abuse handled by a separate moderation pipeline but our API needs to expose hooks, soft delete with tombstones for 30 days.
What this earned you: A full point on resource scoping before you’ve designed anything. The candidate who didn’t ask about threading depth is going to design either too little (no replies, fail) or too much (infinite threading, premature complexity, fail). The candidate who didn’t ask about soft vs. hard delete will get tripped up on the DELETE endpoint later. Every clarifying question is a future trap you’ve defused.
Phase 2 · Resource modeling (the most underrated dimension)
This is where most candidates lose the interview without realizing it. They go straight to “POST /comments” without first identifying what the resources actually are.
Here’s the right move: name the nouns, name their relationships, and name the lifecycle of each one — out loud — before drawing a single endpoint.
“Let me identify the resources first. I see four real ones in this domain.
Comment — the primary resource. A comment has an ID, an author, a body, a parent (which is either a Post or another Comment in the case of a reply), a created-at timestamp, an edited-at timestamp, a state (active or deleted), and a like count.
Post — already exists in the broader Instagram API. Comments belong to it. We don’t design it here, but we need to reference it.
Like — a like on a comment is its own resource, not a field on the comment. This matters because likes have their own lifecycle: they’re created, they can be removed, they have an author, and we may want to query them independently (’show me all the comments this user liked’). Inlining the like as a counter on the Comment resource is fine for display, but the like itself is a resource.
Reply — I want to call this out explicitly even though structurally a Reply is just a Comment with a parent_comment_id. The reason is that the API surface for replies is meaningfully different — listing replies is a different access pattern than listing top-level comments, and we’ll want a dedicated endpoint for it. So conceptually it’s the same resource, but at the API layer it gets its own path.
A few things I’m choosing not to model as separate resources: mentions and hashtags inside a comment body. Those are parsed from the body server-side and returned as enriched fields, but they’re not addressable resources. Their state is fully derived from the comment text.”
That last paragraph is the move. The candidate isn’t just listing what they’re including — they’re explicitly listing what they’re excluding and why. That’s the senior-level signal.
What this earned you: Two distinct points. One on resource identification (you found Like as its own resource, which most candidates miss), and one on negative design decisions (you explicitly excluded mentions/hashtags as resources with a justification). The interviewer is now thinking: this person has actually designed APIs before.
Phase 3 · Endpoint design
Now — and only now — you draw the endpoints. Keep it tight, keep it RESTful, and keep it consistent.
“Here’s the endpoint surface. I’m going to organize it by resource.
Comments on a post:
GET /v1/posts/{post_id}/comments POST /v1/posts/{post_id}/comments GET /v1/comments/{comment_id} PATCH /v1/comments/{comment_id} DELETE /v1/comments/{comment_id}Replies to a comment:
GET /v1/comments/{comment_id}/replies POST /v1/comments/{comment_id}/repliesLikes on a comment:
POST /v1/comments/{comment_id}/likes DELETE /v1/comments/{comment_id}/likes GET /v1/comments/{comment_id}/likesA few design choices I want to call out.
First, I’m using nested paths for creation and listing (
/posts/{id}/comments) but flat paths for fetching, updating, and deleting a single comment (/comments/{id}). This is the convention most modern APIs converge on, including Stripe and GitHub. The reason is that creation and listing are scoped operations — you only ever create or list comments in the context of a post — but once a comment exists, it has its own globally unique ID and doesn’t need its parent context to be addressed. Forcing the client to know the post_id to fetch a single comment is needless coupling.Second, I’m using PATCH not PUT for comment edits, because comment updates are partial — the client is only changing the body, not replacing the whole comment. PUT would imply replacement semantics, which would mean the client has to send the full resource state, which is brittle.
Third, likes are a sub-resource, not a verb. I considered
POST /v1/comments/{id}/likeas a verb, but that’s RPC-style, and it doesn’t compose withGET /likesorDELETE /likesas cleanly. Treating likes as a resource collection lets all three operations live in one place.Fourth, I am not including a
POST /v1/commentstop-level endpoint. Every comment must be created in the context of a parent (a post or another comment). Allowing a top-level create would let clients construct orphan comments, which makes no sense in this domain.”
What this earned you: Two more points. One on REST consistency, one on the explicit articulation of negative choices (”I considered X but chose Y because”). The interviewer is now writing “strong API design instincts” in their notes.
Phase 4 · Request/response shapes
Now the payloads. This is where you show that you think about the clients that will consume your API, not just the server that produces it.
“Let me show what a comment looks like in a response.
{ \"id\": \"c_8f3k2j1\", \"post_id\": \"p_29fj38a\", \"parent_comment_id\": null, \"author\": { \"id\": \"u_92jf81\", \"username\": \"arslan\", \"display_name\": \"Arslan A.\", \"avatar_url\": \"https://...\" }, \"body\": \"Great post!\", \"mentions\": [], \"like_count\": 42, \"reply_count\": 3, \"viewer_has_liked\": true, \"state\": \"active\", \"created_at\": \"2026-04-13T14:32:11Z\", \"edited_at\": null }A few choices in here I want to defend.
IDs are prefixed strings, not raw integers.
c_8f3k2j1instead of8392011. This is for two reasons. One, it makes IDs self-describing in logs and debugging — you can tell at a glance what kind of resource you’re looking at. Two, it lets us migrate the underlying ID format later (from autoincrement to UUID to Snowflake) without breaking clients.The author is embedded, not just an ID. This is a calculated tradeoff. Embedding the author bloats the payload and risks staleness, but it eliminates the N+1 problem on the client — listing 30 comments without embedding means 31 round trips to render the feed. For a high-read endpoint this is the right call. The staleness risk is bounded because usernames and avatars rarely change.
viewer_has_likedis a viewer-specific field. Not ‘has_liked,’ which would be ambiguous. The naming conventionviewer_*makes it explicit that this field is computed for the authenticated user making the request. This is a Facebook/Instagram convention I’d carry over because it eliminates an entire class of bugs where clients assume a global field is viewer-scoped.Counts (
like_count,reply_count) are denormalized into the comment. They’re not source-of-truth — the source of truth is the count of rows in the likes and replies tables — but recomputing on every read is too expensive. We update them via a counter service or a streaming aggregate.
mentionsis an array, even when empty. I would never returnnullfor a list field. Always an empty array. Clients shouldn’t have to writementions || []everywhere.Timestamps are ISO 8601 in UTC. Not Unix epochs, not localized strings. ISO 8601 is unambiguous, sortable as text, and human-readable in logs.”
What this earned you: Three more points, scattered across response design, denormalization tradeoffs, and the philosophical consistency of the payload (every field has a defensible reason). The viewer_has_liked callout is the kind of detail that comes from production experience and is impossible to fake.
Phase 5 · Pagination
This is where API design interviews start filtering candidates hard. The wrong choice here is so obviously wrong to an experienced reviewer that it can sink an otherwise strong interview.
“For listing comments, the question is offset-based pagination versus cursor-based. The default-but-wrong answer is offset.
Offset pagination —
?page=2&limit=20— has two killer problems for a feed like comments. One, it doesn’t handle inserts. If new comments arrive between page 1 and page 2, the user sees duplicates, because the offset shifts. Two, deep pagination isO(offset)in the database — fetching page 1000 means scanning and discarding 19,980 rows. For a viral post with millions of comments, this is unworkable.Cursor-based pagination is the right answer. The cursor is an opaque token representing ‘where I left off.’ Internally it’s typically the timestamp + ID of the last item, base64-encoded so clients treat it as opaque.
The endpoint looks like:
GET /v1/posts/{post_id}/comments?limit=20&cursor=eyJ0cyI6Li4ufQResponse:
{ \"data\": [ {comment}, {comment}, ... ], \"page_info\": { \"has_next_page\": true, \"end_cursor\": \"eyJ0cyI6Li4ufQ\", \"has_previous_page\": false, \"start_cursor\": \"eyJ0cyI6Li4ufQ\" } }A few things to defend here.
Cursors are opaque. Clients should never parse them. If they’re just base64 of
{timestamp, id}today, we can change the encoding tomorrow without breaking anyone.The cursor encodes a tiebreaker. Pure timestamp cursors break when two comments share a timestamp. Always include a secondary key — usually the comment ID — so the ordering is total, not partial. This bug shows up exactly once in production and is catastrophic; you don’t want to learn it the hard way.
has_next_pageis a boolean, not an item count or page number. Total counts on infinite feeds are expensive and rarely useful — they’d require scanning all comments to compute. Telling the client ‘there’s more’ is enough.Sort order has to be specified. Newest first by default for top-level comments. But Instagram actually sorts by ‘top’ (an engagement-weighted ranking) for popular posts, so I’d add
?sort=top|recentas a parameter and let the client choose. The cursor is sort-aware — you can’t paginate with a cursor from one sort order against another sort order.”
What this earned you: A full point on pagination, plus a half-point on the tiebreaker callout (which is rare and shows scar tissue from real production bugs). If you only mention offset or hand-wave pagination, you cap at a 3 on this dimension no matter how good the rest of the interview is.
If you want a deeper dive into the pagination, idempotency, and rate-limiting patterns that show up across system design and API design interviews, Grokking the System Design Interview walks through the canonical questions where each of these patterns appears — they’re the same patterns recycled across Twitter, Uber, Stripe, and dozens of other questions, so building fluency once pays out across the entire question pool.
Phase 6 · Idempotency (the dimension nobody plans for)
This is where you prove you’ve actually built APIs that real clients call over flaky networks.
“POST endpoints have an idempotency problem. If a client posts a comment, the request times out, and the client retries — does the comment get created twice?
The naive answer is ‘use a transaction.’ That doesn’t help, because the transaction succeeded server-side; the response just didn’t make it back to the client. The client has no way to know whether to retry.
The right answer is client-supplied idempotency keys. The client generates a UUID per logical create operation and sends it in a header:
POST /v1/posts/p_29fj38a/comments Idempotency-Key: 9a8b7c6d-...-...Server-side, we maintain an idempotency store keyed by
(user_id, idempotency_key)with a TTL of 24 hours. On the first request, we process normally and store the response keyed by that idempotency key. On any retry with the same key, we return the cached response without re-processing. Stripe popularized this pattern and it’s now table stakes for any API that handles state-changing operations.A few subtleties.
The idempotency key is scoped per user. Two different users could use the same key by coincidence; that’s fine because the keys are namespaced.
The TTL is finite. 24 hours is enough to handle retries from any reasonable client; longer than that and the storage cost gets meaningful.
Idempotency is only required for mutating endpoints — POST, PATCH, DELETE that have side effects. GET is naturally idempotent. PATCH and DELETE on a specific resource ID (
PATCH /comments/{id}) are also naturally idempotent if implemented correctly — patching the same comment twice should yield the same result. Only POST to a collection (which creates a new resource) needs the key.What if the second request arrives with the same key but a different body? That’s a client bug — they reused a key for a different operation. The server should reject it with a 422 and an explicit error. Silently treating it as the same operation hides bugs.”
What this earned you: This is the single highest-signal section of the interview. Most candidates either don’t mention idempotency at all (cap at 3 overall) or hand-wave it (cap at 4). Discussing idempotency keys with the right scoping rules and the body-mismatch case is staff-level signal. If you do this section right, you’ve moved from hire to strong hire in the interviewer’s notes.
Phase 7 · Versioning
Versioning is a question of philosophy, not just implementation. The interviewer wants to know whether you have a strategy.
“Three real options for versioning a public API.
URL versioning —
/v1/comments,/v2/comments. Pros: explicit, easy to route, easy to deprecate. Cons: encourages big-bang version bumps, and clients have to migrate everything at once when v2 ships.Header versioning —
Accept: application/vnd.instagram.v2+json. Pros: cleaner URLs, lets you version individual resources. Cons: harder to test in a browser, harder to discover, easy to forget.Date-based versioning —
Instagram-API-Version: 2026-04-13. This is what Stripe and Shopify do. Each client pins to a specific date, and breaking changes ship on specific dates with documentation. Pros: incremental, lets you ship breaking changes on individual fields without a big-bang version bump. Cons: more complex server-side because you need to maintain transformation layers.For Instagram comments — a public API with millions of third-party integrations — I’d choose URL versioning at the major level + additive evolution within a major version. Major versions are rare and well-announced; within a major, we only ever add fields, never remove them. Clients can ignore unknown fields. If we need to remove a field, we deprecate it with a sunset header for at least 12 months before it disappears, and we ship the change at a major version boundary.
One non-obvious choice: I’d return a
Sunsetheader and aDeprecationheader on responses for endpoints that are scheduled for removal. These are standard HTTP headers (RFC 8594) that let well-behaved clients log warnings without breaking. Few APIs do this and it’s a quality signal.”
What this earned you: A full point for having a coherent versioning philosophy and knowing the alternatives well enough to compare. The Sunset/Deprecation header reference is a small flex that signals you keep up with HTTP RFCs, not just blog posts.
Phase 8 · Rate limiting and errors
Last major dimension. The interviewer wants to see that you think about the system under abuse, not just under happy-path load.
“Rate limiting on a comments API has to think about three different abuse vectors.
One, per-user write rate limits. A normal human posts maybe a few comments per minute; a spam bot posts hundreds. I’d cap at 30 comments per minute per user, with a sliding window. Burst allowance of 10 in the first 10 seconds to handle legitimate rapid commenting.
Two, per-IP rate limits. Catches script-driven abuse where one attacker rotates user accounts but comes from the same source. More conservative — maybe 100 requests per minute across all endpoints.
Three, per-app rate limits for third-party integrations. Each registered API consumer gets a quota negotiated as part of their developer agreement.
Rate limit responses use standard headers:
X-RateLimit-Limit: 30 X-RateLimit-Remaining: 12 X-RateLimit-Reset: 1745000000When exceeded, return 429 Too Many Requests with a
Retry-Afterheader so clients know how long to back off. Don’t just drop the request — clients need a clear signal to implement exponential backoff.On errors more broadly, I’d use standard HTTP status codes consistently: 200 for success, 201 for resource creation, 204 for successful DELETE with no body, 400 for malformed requests, 401 for unauthenticated, 403 for unauthorized (the distinction matters), 404 for not found, 409 for conflicts (like trying to like a comment you already liked), 422 for validation errors, 429 for rate limited, 5xx for server errors.
Error response bodies follow a consistent shape:
{ \"error\": { \"code\": \"comment_too_long\", \"message\": \"Comment body exceeds the 2200 character limit.\", \"field\": \"body\", \"request_id\": \"req_8a7f3...\" } }Three things in there worth defending. The error code is a stable string, not the human message — clients should branch on the code, not parse English. The field points the client at exactly what was wrong, which is the difference between a great DX and a frustrating one. The request_id lets a developer file a support ticket with a single value that the server team can grep for in logs.”
What this earned you: The error response shape with code, field, and request_id is a small detail with outsized signal value. The 401-vs-403 distinction is another thing that’s easy to get wrong and almost no junior engineers know. Each of these is a half-point that adds up.
What the interviewer’s debrief looks like
After this 45 minutes, the interviewer’s notes look something like:
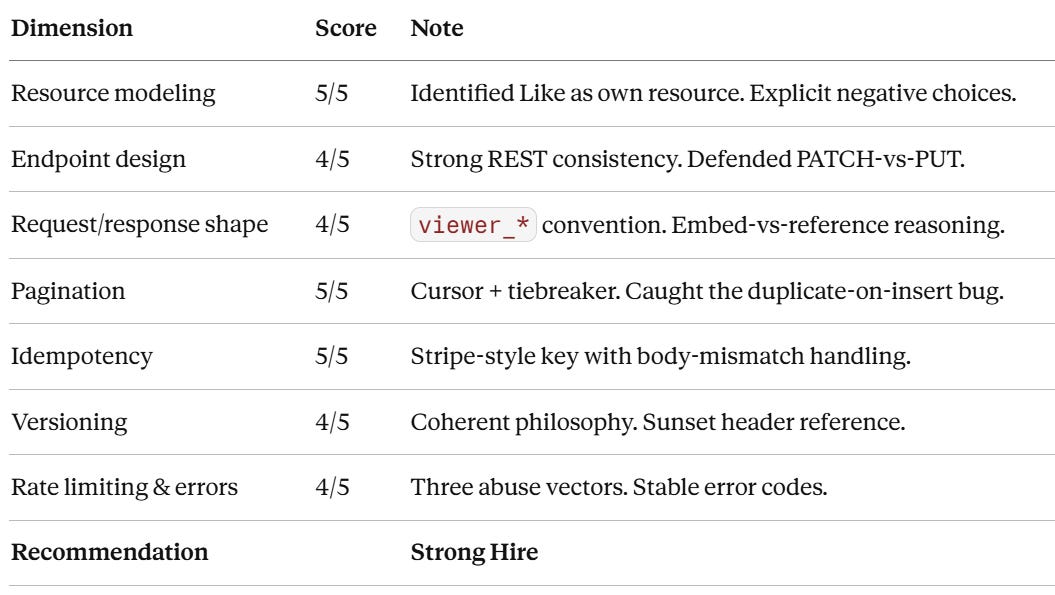
Notice how every “5” comes from a section where the candidate did something negative or non-obvious — exclude a resource, identify a tiebreaker bug, handle a body mismatch. The fives come from the moves nobody else makes. That’s the real lesson of this rubric.
The eighth dimension: consistency of thought
Here’s the thing that ties this whole interview together. None of the seven dimensions above are that hard individually. The hard part is doing all of them in one interview, in a way that coheres — where your pagination strategy fits your sort order, your idempotency keys fit your error model, your versioning philosophy fits your endpoint style, and the whole thing reads like it was designed by one person with one taste rather than a checklist of pattern reaches.
That’s the difference between “this candidate knows API design” and “this candidate has built APIs.” It’s also the only dimension that can’t be studied — it has to be earned through reps. Mock the question above with a friend. Then mock five more. Then read three real production API docs (Stripe’s, GitHub’s, and Twilio’s are the canonical study set) and ask yourself what each of their decisions earned them.
The interviewer is not testing whether you’ve memorized the seven dimensions. They’re testing whether you’ve designed enough APIs that the dimensions are no longer dimensions to you — they’re just taste.