
Arrays and Strings Explained: Memory, Indexing, and Why Some Operations Are Slow
A beginner's guide to how arrays and strings are stored in memory, why accessing an element by index is O(1), and why inserting or deleting in the middle is O(n).


Arrays are the first data structure almost everyone learns, and also the one most people never really understand.
You know how to use one: make a list, grab the third element, loop over it.
But ask why grabbing the third element is instant while inserting an element in the middle is slow, and most beginners draw a blank.
That gap matters, because arrays are the foundation everything else is built on, and the answer to “why is this operation fast or slow?” almost always traces back to how the data physically sits in memory.
Once you can picture that, a huge amount of programming stops being arbitrary rules to memorize and starts being obvious consequences of one simple layout.
This post explains arrays and strings from the ground up: how they’re actually stored, why indexing is O(1) (instant), why inserting or deleting in the middle is O(n) (slow), and how strings are really just arrays of characters with one important twist.
No prior knowledge assumed, and by the end you’ll understand not just what arrays do but why they behave the way they do.
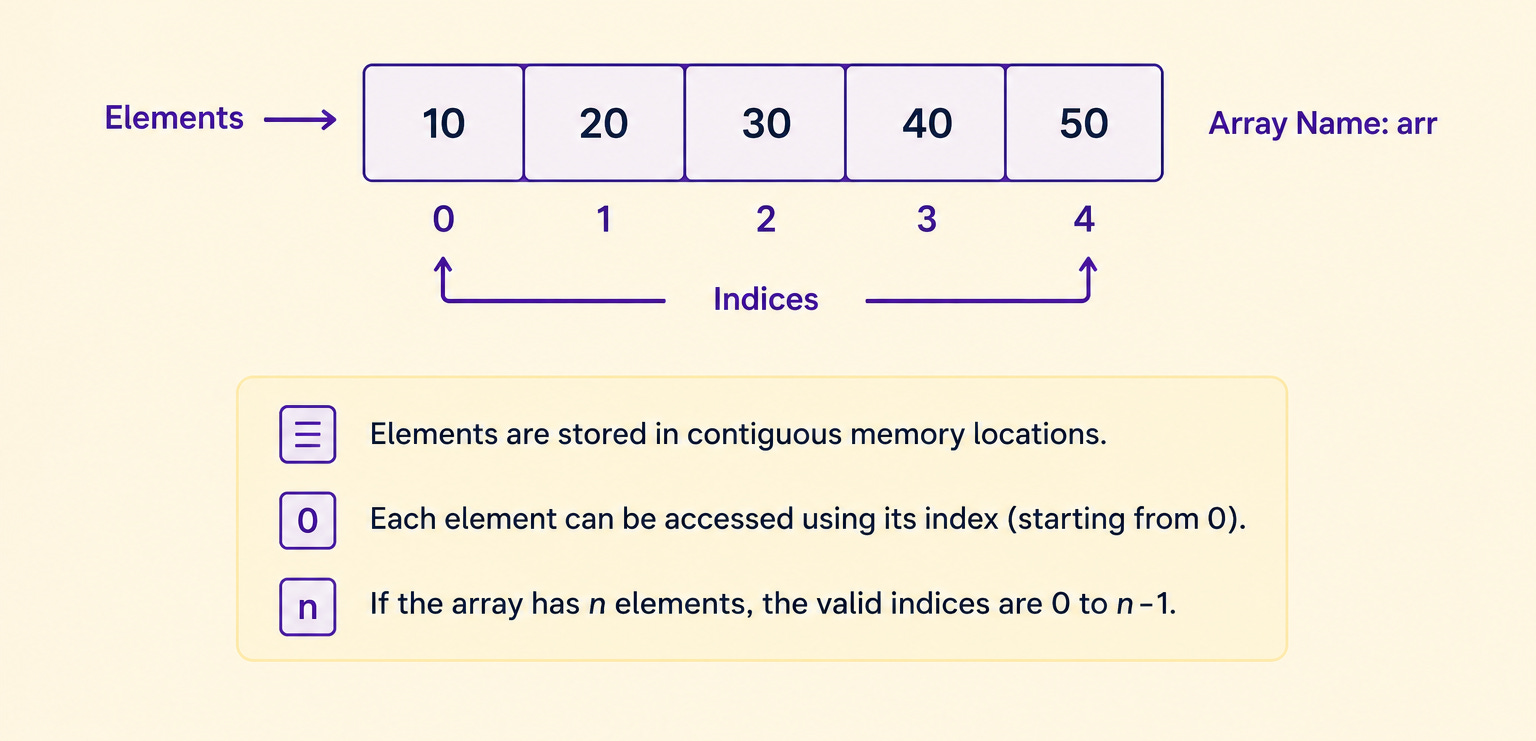
What Is an Array
An array is a block of memory where all the elements sit right next to each other, in one continuous run.
Picture your computer’s memory as an enormous row of numbered boxes, each able to hold one value.
When you create an array of, say, five numbers, the computer finds five empty boxes in a row and reserves them.
The array isn’t scattered around memory; it’s one contiguous stretch.
This is the defining property of an array, and it’s called contiguous storage.
That single design choice, “keep everything in a continuous block”, is the source of every strength and every weakness an array has.
Almost everything below follows directly from it.
There’s one more piece.
Each box in memory has an address, like a house number on a street.
Because the array’s elements are contiguous, the computer only needs to remember one thing: the address of the very first element.
Everything else can be calculated from there, which is exactly what makes indexing so fast.
Why indexing is instant (O(1))
When you write arr[3] to get the fourth element (arrays count from zero), it feels like the computer searches for it.
It doesn’t.
It does a single piece of arithmetic.
Because the elements are contiguous and each element takes up the same fixed amount of space, the computer can calculate exactly where element number 3 lives.
The formula is simple: take the address of the first element, then jump forward by 3 times the size of one element.
One multiplication, one addition, and the computer lands precisely on the box it wants. It never looks at elements 0, 1, or 2 at all.
This is why accessing arr[3] and accessing arr[3000000] take the same amount of time.
The computer isn’t walking through the array counting; it’s computing an address and jumping straight there.
The position doesn’t matter, the work is identical. That “same time regardless of size or position” property is exactly what O(1), or constant time, means. It’s the array’s superpower, and it’s a direct gift of contiguous storage.
A quick mental check: imagine a row of identical lockers, all the same width, starting at locker 100.
To find locker 100 plus 47, you don’t open lockers one by one. You know each is the same width, so you walk straight to the 47th one down. Same idea.
The uniform size and the known starting point are what make the jump instant.
Why inserting or deleting in the middle is slow (O(n))
Now the flip side, and it comes from the exact same contiguous layout that made indexing fast.
The strength and the weakness are two faces of one design.
Suppose you have the array [10, 20, 30, 40, 50] and you want to insert 99 at the front, so it becomes [99, 10, 20, 30, 40, 50].
Remember that every element sits in a specific box, right next to its neighbors, with no gaps.
To put 99 at the front, there’s no empty box there, it’s occupied by 10. So the computer has to shift every existing element one box to the right to make room: 50 moves over, then 40, then 30, 20, and 10, and only then can 99 go in the front box.
For a 5-element array that’s 5 shifts, no big deal. But for an array of a million elements, inserting at the front means shifting a million elements over by one.
The work grows in direct proportion to the size of the array. That’s O(n), or linear time, the work scales with n, the number of elements.
Deleting from the middle has the same problem in reverse: remove an element and you leave a gap, which violates the “no gaps, contiguous” rule, so everything after it must shift left to close the hole.
Again, proportional to how many elements come after the deletion point.
The key insight: inserting or deleting is slow not because finding the spot is slow (that part is fast), but because maintaining the contiguous, no-gaps layout forces you to move everything else.
The very property that makes indexing instant is what makes middle-insertion expensive.
You can’t have one without the other; it’s a fundamental tradeoff baked into how arrays work.
There’s one happy exception worth knowing: inserting or deleting at the very end of an array is usually fast, because nothing has to shift, you’re just filling the next empty box or clearing the last one.
This is why “append to the end” is cheap while “insert at the front” is expensive, even though both are insertions.
A quick summary of array operation costs
Putting it together, here’s how the common operations cost out, and notice how every cost traces back to the contiguous layout:
Accessing an element by its index is O(1), instant, because the address is computed directly.
Searching for a value when you don’t know its position is O(n), because you have to check elements one by one until you find it.
Inserting or deleting at the end is typically O(1), nothing shifts. Inserting or deleting at the beginning or middle is O(n), because everything after the spot must shift to preserve contiguity.
If you remember only one thing: arrays make position-based access incredibly fast and structure-changing in the middle relatively slow, and both facts come from the same contiguous storage.
A note on “dynamic” arrays and growing
You might wonder: if an array reserves a fixed block of boxes, what happens when you keep adding elements and run out of room?
In many languages, the lists you use (like Python’s list or Java’s ArrayList) are dynamic arrays, which handle this for you.
When a dynamic array fills up, it quietly does something clever: it reserves a new, larger block of memory (often double the size), copies all the existing elements over, and continues.
That occasional copy is expensive, O(n) for the copy itself, but because it happens rarely and the array doubles each time, the average cost of appending stays effectively O(1) when spread across many appends.
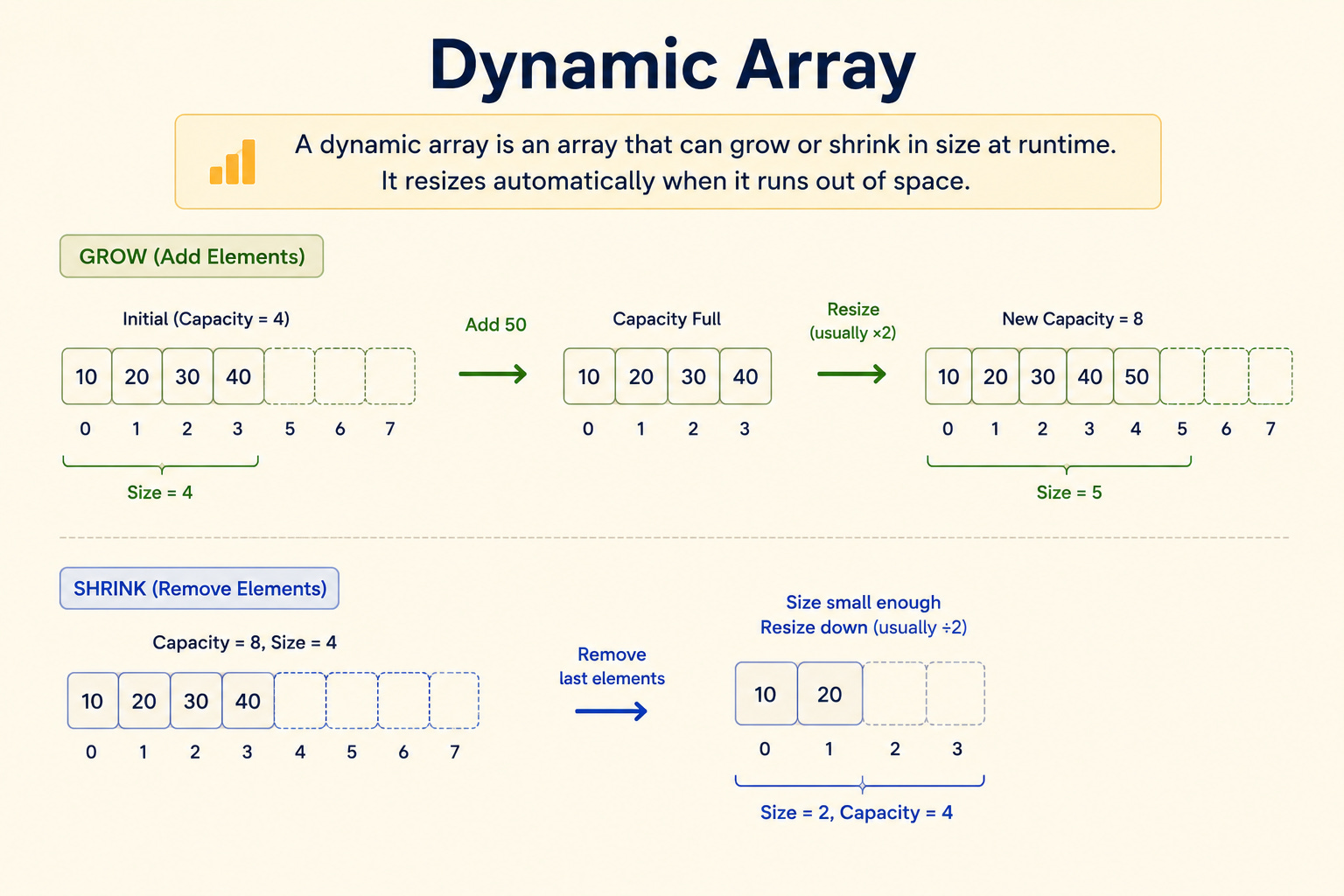
You don’t need the deep math here, just the intuition: appending is cheap almost always, with an occasional invisible resize that averages out.
This is why you can keep adding to a list without thinking about size, even though a raw array underneath has fixed boxes.
Strings are arrays of characters, with one twist
Here’s a connection that makes a lot of things click: a string is essentially an array of characters.
“hello” is stored much like an array ['h', 'e', 'l', 'l', 'o'], contiguous in memory, which means everything you just learned applies.
Accessing the character at a given position is O(1). Scanning a string for a substring is O(n).
The same contiguous-storage logic carries straight over.
But strings have one important twist in many languages: they’re often immutable, meaning once created, a string cannot be changed in place.
In Python, for example, trying to do s[0] = 'H' to capitalize the first letter raises an error, because you’re not allowed to modify the existing string’s boxes.
This has a practical consequence beginners hit constantly.
When you “change” a string, say by concatenating (greeting = greeting + "!"), you’re not editing the original.
The computer creates an entirely new string in fresh memory, copies the old contents plus the addition into it, and points your variable at the new one. For a single change that’s fine.
But building a long string by repeatedly concatenating in a loop is secretly expensive, because each concatenation copies the entire string so far.
A loop that adds one character at a time to a growing string can quietly become O(n²), since each of the n steps copies up to n characters.
The fix, which you’ll see experienced programmers use, is to collect the pieces in a list and join them once at the end, or use a dedicated string-builder, so you copy everything a single time instead of on every step.
Knowing why (immutability forces a fresh copy on every concatenation) is what lets you recognize and avoid the trap.
Why this matters in practice and in interviews
This isn’t abstract trivia.
Understanding the array’s layout lets you predict performance and explain your choices, which is exactly what interviews probe and what real engineering requires.
When you reach for a data structure, you’re implicitly choosing its tradeoffs.
If your code mostly reads elements by position, an array is perfect, that’s O(1) access.
If your code constantly inserts and deletes in the middle, an array may be the wrong choice, and a different structure like a linked list (which trades away fast indexing to get fast middle-insertion) might fit better.
The whole reason multiple data structures exist is that each makes a different tradeoff, and arrays make the specific bargain of fast access for slow middle-modification.
In an interview, being able to say “I’ll use an array here because I need fast random access, and I’m not inserting in the middle, so the O(n) insertion cost won’t bite us” demonstrates exactly the judgment being graded.
It shows you understand not just how to use the structure but why it behaves as it does, which is the difference between memorizing and understanding.
Frequently asked questions
Why do arrays start counting at zero?
Because the index is really an offset from the start. Element 0 is “zero steps from the beginning,” element 3 is “three element-widths from the beginning.” Zero-based indexing makes the address calculation clean, the first element is exactly at the starting address.
Is accessing the last element slower than the first?
No. Both are O(1), because the computer computes the address directly in either case. It never walks through the array, so position is irrelevant to access speed.
Why is searching O(n) if access is O(1)?
Access is fast only when you know the position. Searching means you don’t know the position and have to check elements one by one until you find the value, which in the worst case means looking at all n of them.
What’s the difference between an array and a list?
Terminology varies by language. A raw array often has a fixed size; a “list” (like Python’s list) is usually a dynamic array that grows automatically. Underneath, the dynamic version is still a contiguous array that occasionally resizes itself. The core behavior, fast indexing, slow middle-insertion, is the same.
Why are strings immutable in some languages?
Immutability enables optimizations and avoids whole categories of bugs (a string you pass to a function can’t be secretly altered). The tradeoff is that “modifying” a string actually creates a new one, which is why repeated concatenation in a loop can be slow.
When should I NOT use an array?
When your main operation is inserting or deleting in the middle frequently, since that’s O(n) each time. If that’s your workload, look at structures designed for it, like linked lists or other specialized collections.
The bottom line
An array is a contiguous block of memory, all elements packed side by side, and that single fact explains everything about it.
Because the elements are contiguous and uniformly sized, the computer can compute any element’s address directly, making access by index O(1), instant, regardless of position or size. But that same contiguous layout means inserting or deleting in the middle forces every later element to shift, making those operations O(n).
Strings are arrays of characters that follow the same rules, with the twist that they’re often immutable, so “changing” one really makes a new copy.
Understanding this one layout, and the tradeoff it creates, turns a lot of programming from arbitrary rules into predictable consequences.
The next time an operation is surprisingly fast or slow, your first question should be “what does this look like in memory?”, and for arrays, you now know the answer.