
How System Design Interviews Actually Changed in 2026 (and What Replaced the Old Playbook)
Side-by-side: the old question, the new question, the old expected answer, the new expected answer — with sample prompts from candidates who interviewed in the last 90 days.

Most “system design is evolving” articles are history lessons. They walk you through 20 years of distributed systems, tip their hat to the cloud, mention AI, and wrap up with something vague about staying curious. Cool. That doesn’t help you in the interview next Tuesday.
This article is a diff, not a history. For each of the canonical system design questions that’s been in the rotation for a decade, I’m going to show you four things, side by side:
The old question (still asked, but with a different rubric behind it)
The new question (the 2026 version, sometimes a subtle reframing, sometimes an entirely new problem)
The old expected answer (what earned a “hire” in 2019)
The new expected answer (what earns a “hire” in 2026)
And I’ll include sample prompts from candidates who actually sat these interviews in the last 90 days. Names withheld, questions paraphrased to respect NDAs, but the shape is real.
Let’s get into the diff.
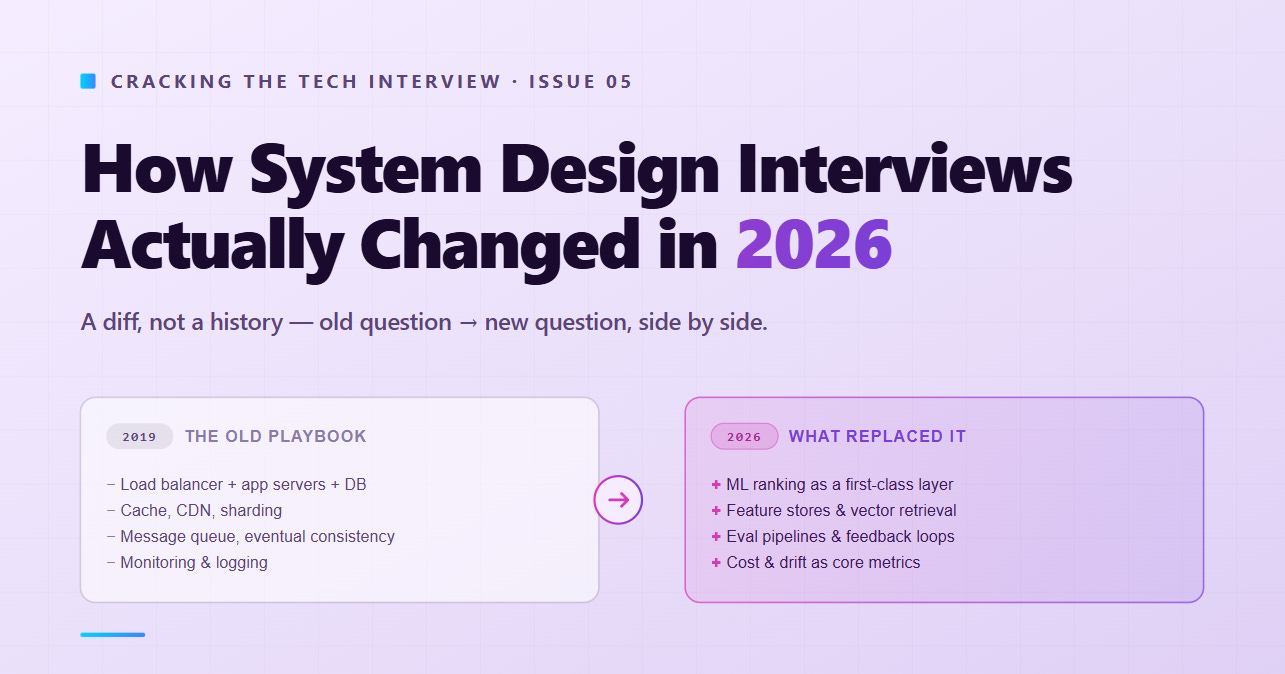
The old playbook (what used to be enough)
Before we show what’s changed, here’s what the old canonical system design answer looked like. If you learned system design between roughly 2017 and 2023, this is the mental model you were trained on:
Clarify requirements and scale numbers (QPS, storage, users)
Draw a client → load balancer → app servers → database sketch
Add a cache (Redis or Memcached)
Add a CDN for static content
Shard the database when traffic grows
Add a message queue for async work
Mention eventual consistency and CAP
Wave hands about monitoring, logging, and multi-region failover
This sequence earned a hire at most FAANG companies in 2019. At some it still does in 2026 — but at the top of the stack, it now caps you at a 3 out of 5 on architecture, which means you’re one weak dimension away from a downlevel. The rubric moved out from under the answer.
Here’s what moved, question by question.
Question 1 · “Design Twitter”
Status: Still asked, but reframed.
Old version: “Design Twitter. Users can post tweets, follow other users, and see a feed of tweets from people they follow.”
New version (90-day sample): “Design Twitter, including the home feed ranking. Users should see a personalized timeline, not just a reverse-chronological feed of people they follow. Walk me through the whole system, and spend real time on the ranking pipeline.”
What changed in the question: Ranking is no longer an afterthought. The old version let you hand-wave feed ordering (”we’ll rank by recency and some signals”) and spend 90% of the interview on fanout strategies and storage. The new version explicitly asks for the ranking pipeline as a first-class component. This is because every feed at scale is now ML-ranked, and interviewers want to see that you understand what that means as a system.
What the old expected answer looked like:
“I’d use a fanout-on-write approach for most users — when you tweet, we push it to the feed inboxes of all your followers. For celebrities with millions of followers, we’d switch to fanout-on-read — we pull their tweets at read time to avoid the write amplification. We’d store feed inboxes in Redis. The feed is sorted by timestamp.”
Solid. In 2019, that’s a 4 out of 5.
What the new expected answer looks like:
“Fanout strategy is table stakes — hybrid fanout, fanout-on-write for normal users, fanout-on-read for celebrities, I’ll sketch that quickly. But the interesting system here is the ranking pipeline, so let me spend most of the time there.
The feed is no longer a sorted list of tweets; it’s the output of a ranking model applied to a candidate set. So the architecture has three layers I care about.
First, candidate generation. For a given user, we pull candidates from multiple sources — tweets from people they follow, tweets from people those people engaged with, trending tweets in their language, tweets matching topics they’ve shown interest in. Each source produces a few hundred candidates. This runs at read time or near-real-time because freshness matters.
Second, feature hydration. For each candidate tweet, we attach hundreds of features — the author’s recent engagement rate, the viewer’s past interactions with this author, the tweet’s early engagement velocity, content embedding similarity to the user’s interests, time since posting. These features come from a feature store with both online (low-latency key-value lookups) and offline (batch-computed) features.
Third, ranking. The ranker is a model — gradient-boosted trees or a small neural net — that scores each candidate for the viewer. We serve it through a model serving layer like TorchServe or a custom inference service with hard latency budgets. p95 for the entire ranking call has to be under a couple hundred milliseconds to fit inside the end-to-end feed request.
The feedback loop matters too. Every impression, click, like, retweet, and scroll-past is logged, shipped to the warehouse, and used to retrain the ranker on a regular cadence. The retraining pipeline itself is a system I’d diagram separately.
For reliability, I’d have a fallback — if ranking is slow or down, we fall back to a reverse-chronological feed from the candidate set. Users get a degraded but usable experience.”
What the 2019 candidate would have missed entirely: The entire middle layer. Feature stores, candidate generation as a distinct phase, online vs. offline feature serving, and the training-serving split. These aren’t edge cases anymore — they’re the primary thing being scored on a feed question in 2026.
Question 2 · “Design a URL shortener”
Status: Downgraded. Still asked at the phone-screen level, rare at the onsite.
Why it’s downgraded: The URL shortener was a beloved starter question because it touched hashing, database design, and cache design in a compact package. But it doesn’t exercise any of the skills that now matter most. There’s no ML in a URL shortener. There’s no non-deterministic behavior. The hard parts are all solved problems with well-known answers.
If you get this question in 2026, you’re probably in a phone screen or an early-career loop, and the bar is basically unchanged from 2019. Answer it cleanly, hit the key decision points (base62 encoding, collision handling, read-heavy caching, maybe a counter service), and move on. Don’t try to inject AI into it — there’s nowhere for it to go, and forcing it looks desperate.
Question 3 · “Design a chat application”
Status: Still asked, reframed significantly.
Old version: “Design WhatsApp. Users can send text messages to each other, create group chats, and see message history.”
New version (90-day sample): “Design a team chat application like Slack, including search across the entire company’s message history. A user should be able to ask natural-language questions like ‘what did we decide about the pricing launch’ and get a grounded answer.”
What changed: The chat delivery problem is largely solved and well-understood. What’s new is that chat history has become the knowledge base the company runs on, and the interesting system design question is no longer how do messages get delivered but how do messages get searched, synthesized, and made queryable. This is effectively a RAG question disguised as a chat question.
What the old expected answer looked like:
“Clients connect over WebSocket to a gateway server. Messages are written to a write-ahead log and fanned out to the recipient’s connected sessions. History is stored in a sharded database partitioned by channel or conversation ID, with a time-based secondary index for pagination. We’d use a queue for offline message delivery — when a user comes back online, we replay missed messages. For search, Elasticsearch on a tailing index of the message store.”
What the new expected answer looks like:
“The real-time delivery part is well-understood — WebSocket gateways, fanout, offline queues, at-least-once delivery with client-side deduplication. I’ll sketch that briefly and then spend real time on the search layer, because that’s where this question actually lives in 2026.
Company-wide semantic search over chat history is a retrieval-augmented generation problem. I need three layers on top of the normal chat storage.
Ingestion and embedding. Every message — or more realistically, every small window of messages grouped into a coherent thread — gets embedded by an embedding model and written to a vector store. I’d chunk by thread rather than by message, because a single message is usually too small to carry meaningful context. The chunking strategy is a hyperparameter I’d tune against an eval set.
Retrieval. When a user asks a question, we embed the question, do a vector similarity search filtered by the user’s channel memberships — ACLs are critical here, we cannot surface messages from channels the user doesn’t belong to — rerank the top candidates with a cross-encoder, and pass the top few threads to the generation layer. I’d use hybrid retrieval because chat is full of exact-match patterns: project codenames, error codes, person names, ticket IDs. Pure vector search misses those; BM25 plus vector scored together does much better.
Generation. An LLM takes the retrieved threads and the question and generates an answer with citations to the source threads. The user can click through to the actual messages. We use explicit prompt instructions to prevent hallucination (’only answer from the provided context’), and if the retrieved threads aren’t confident enough, we return raw thread links instead of a synthesized answer.
The parts I’d build that aren’t in a 2019 answer. An eval pipeline with a held-out set of question-answer-source tuples that runs on every change to the retrieval stack. Cost per query as a tracked metric. Thumbs-up/down feedback on every answer, logged for retraining and drift monitoring. And a freshness SLA — when a new message is posted in a channel, how quickly does it become searchable? Minutes? Hours? It changes whether ingestion is real-time or batched.”
What the 2019 candidate would have missed entirely: Treating chat history as a corpus to be embedded rather than a stream to be delivered. Also the ACL-aware retrieval — this is one of the single highest-signal moves on any 2026 enterprise RAG question, and it’s the thing most candidates forget.
Question 4 · “Design Google Drive / Dropbox”
Status: Still asked, now almost always comes with a collaboration or AI twist.
Old version: “Design a file storage and sync service. Users can upload files, sync across devices, and share with other users.”
New version (90-day sample): “Design a collaborative document platform like Notion. Multiple users can edit the same document in real time, and the platform should support AI features — summarize this doc, ask questions about it, generate a draft based on related docs in the workspace.”
What changed: Raw file sync is solved. The interesting parts are collaborative editing (CRDTs or operational transforms, depending on who you ask) and AI features over the workspace corpus. Dropbox-circa-2015 is a 3 out of 5 answer in 2026. The bar is now Notion with AI.
What the old expected answer emphasized:
Chunking files for deduplication, content-addressable storage, sync protocol with deltas, metadata service separate from the blob store, CDN for downloads, conflict resolution via last-write-wins or manual merge.
All still valid. All still required. But it’s now the foundation, not the full answer.
What the new expected answer adds on top:
“On top of the file storage layer, I need a real-time collaboration engine. I’d use CRDTs — specifically something like Yjs — because they’re proven at scale for text documents and handle offline editing gracefully. Each edit is a CRDT operation, broadcast to all connected clients via WebSocket, and persisted to an append-only operation log. Periodically we compact the log into a snapshot.
For the AI layer, every document in a workspace is chunked and embedded asynchronously. When a user invokes ‘ask this document’ or ‘ask across my workspace,’ we retrieve the relevant chunks and pass them to an LLM with the question. The interesting design question is when we re-embed — every edit? Every N edits? On a debounced timer after the user stops typing? For a doc being actively edited this matters because embedding is expensive and retrieval over a constantly-changing doc is tricky.
I’d debounce re-embedding to when a user stops editing for some threshold, and I’d keep a ‘live’ buffer of recent unsaved edits that gets prepended to retrieval context for the author themselves but not for other users asking questions. That way the author sees their own latest state in AI answers, but collaborators don’t see half-written sentences in retrieved context.
For scaling, the interesting bottleneck is the collaboration engine, not storage. At a few thousand concurrent editors on a single document — which happens on high-traffic company all-hands docs — the operation broadcast fanout becomes the constraint. I’d shard by document ID, put a coordinator per shard, and cap the per-document concurrent editor count with a graceful ‘too many editors, enter read-only mode’ fallback.”
What the 2019 candidate would have missed entirely: CRDTs as the modern answer to real-time collab (operational transforms still work but CRDTs are now the default). Debounced re-embedding. The author-vs-collaborator visibility split on live buffers. The concurrent-editor scaling constraint.
Question 5 · “Design a recommendation system”
Status: Still asked. The rubric for this one changed the most.
Old version: “Design the recommendation system for a site like YouTube or Netflix. Users should see personalized video recommendations.”
New version (90-day sample): “Design the recommendation system for a video platform. Walk me through the entire ML system — feature store, training pipeline, serving pipeline, feedback loop, and evaluation. How do you know if a change you ship is actually better?”
What changed: The old question let you get away with a two-layer answer: “we collect user behavior, train a model, serve recommendations.” Done, three boxes, five minutes, move on to discussing storage. The new question is explicitly about the ML system, not just the idea of one. The interviewer wants to see you diagram the training pipeline, the serving pipeline, and the offline evaluation loop as three distinct things.
What the new rubric emphasizes that the old one didn’t:
The training-serving skew problem. If features are computed one way offline (in Spark) and another way online (in your serving code), your model’s predictions at serving time will drift from what was trained. Candidates who don’t mention this miss a point. Candidates who talk about feature stores as the solution — unified online/offline feature definitions — nail it.
Offline evaluation. How do you know if model v2 is better than v1 before you ship it? You need a held-out offline evaluation set with ranking metrics (NDCG, recall at k, etc.) that runs in CI for every model change. This is not optional anymore.
Online evaluation. A/B testing infrastructure is now part of the system design question. How do you split users, how do you measure the outcome, how do you prevent A/B tests from interacting with each other, how do you decide when a test is done.
The feedback loop closing. User impressions, clicks, and watch time get logged, shipped to the warehouse, joined with the features the model saw, and used as training labels for the next model version. The loop from production behavior back to training data is a first-class system component now, not an implementation detail.
Exploration vs. exploitation. Purely exploiting the current model’s predictions leads to filter bubbles and training data collapse — the model only ever sees feedback on items it already thought were good. A real production rec system mixes in exploration (random injections, epsilon-greedy, Thompson sampling, bandits) to keep the training data diverse.
If you can hit all five of those, you’ve gone from a 3 to a 5 on this question. They’re the new bar.
The two dimensions that are now always scored (regardless of question)
Stepping back from the specific questions, there are two dimensions that have moved from “nice to have” to “scored on every question” between 2019 and 2026.
1. Non-determinism literacy. Any system that has an ML model, an LLM, or a ranker in it is now non-deterministic in ways that classical systems weren’t. Candidates who treat ML components as black boxes — “we call the model, it returns a result” — are marked down now regardless of whether they nailed the rest. You’re expected to know about feature stores, training-serving skew, model versioning, drift monitoring, and eval pipelines as first-class system components.
2. Cost as a design constraint. In 2019, cost was a nice-to-have you might mention at the end. In 2026, with LLM API costs dominating the economics of any AI-enabled system, cost per query is a first-class metric that should appear in your design alongside latency and throughput. Candidates who don’t mention cost on an AI-heavy question miss an easy point.
Both of these are the new dimensions I walked through in the 2026 system design rubric article — the point being, they’re not question-specific. They apply to every system design question you’ll get, and they’re the two biggest reasons strong 2019-era candidates are getting surprised by “weak hire” outcomes in 2026 loops.
What actually replaced the old playbook (the condensed version)
If you learned system design from the 2019 playbook and want to update yourself to the 2026 version, here’s the compressed diff:
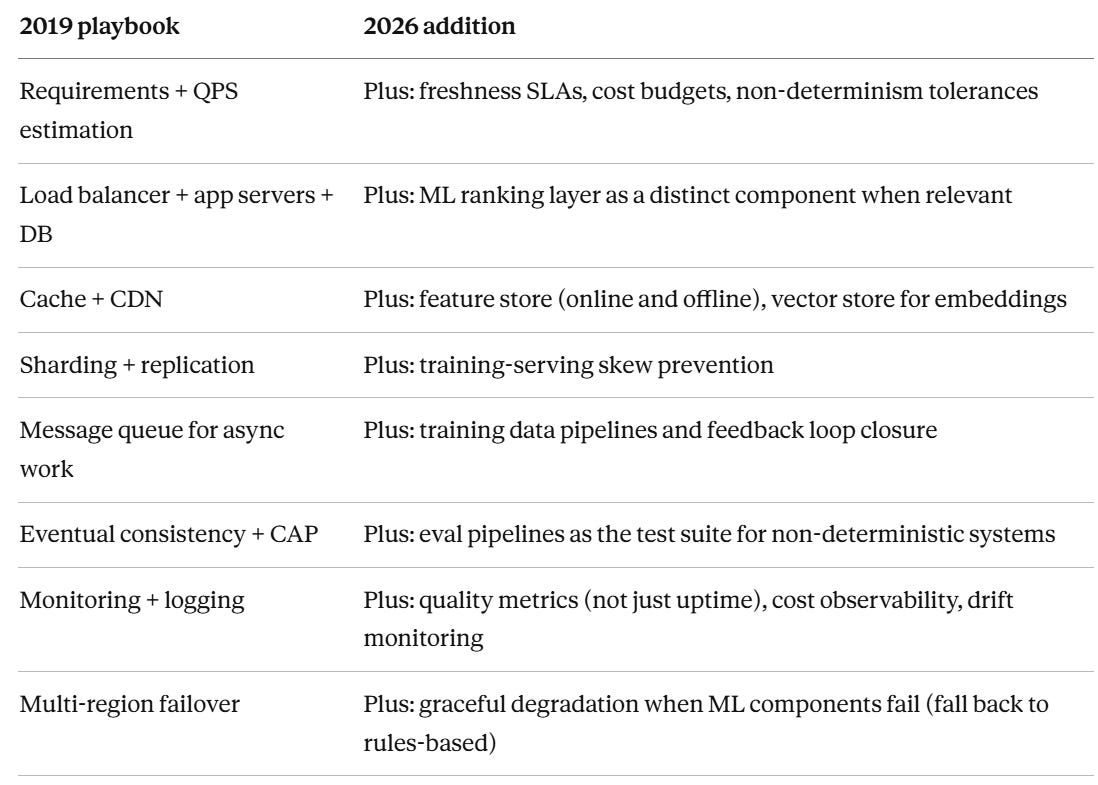
Notice what didn’t get removed from the left column. The classical system design skills haven’t been replaced — they’ve been extended. If you skip the classics to study the new stuff, you’ll fail on architecture. If you skip the new stuff to stay fluent on the classics, you’ll fail on ML literacy and operational maturity. You need both.
How to actually update your prep
Three concrete things to do this week if you’re interviewing in the next 60 days.
One, re-solve one question you already know. Pick “design Twitter” or “design Netflix recommendations” — whichever you’ve practiced before — and re-solve it with the new rubric in mind. Actively force yourself to include the ML ranking pipeline, the feature store, the feedback loop, and the eval pipeline. You’ll immediately see where your muscle memory is outdated.
Two, pick one unfamiliar question and solve it cold. Something like “design a semantic search system for internal company docs” or “design the AI summarization feature for Notion.” These questions simply didn’t exist in 2019. If you haven’t solved at least three of them, you’re walking in cold.
Three, read a real post-mortem from a production ML system. The Uber eng blog, the Netflix tech blog, and the Meta AI research blog all have post-mortems that read like the inside of a system design interview. One of them is worth more than a week of reading interview prep material, because they tell you what actually breaks in production — which is what the interviewer is secretly asking you to predict.
The system design interview hasn’t become harder. It’s become bigger. More surface area, more dimensions, more things the interviewer is listening for. The candidates who still use the 2019 playbook aren’t failing — they’re just consistently getting downleveled by one. That gap compounds across an entire career. The fix is updating the playbook, not abandoning it.