
Inside the Amazon 2026 Loop: Rounds, Rubric, and What Each Interviewer Scores You On
A complete breakdown of how Amazon's SDE interview works in 2026. The five rounds, the Bar Raiser, the Leadership Principles weighting, and what a "hire" debrief actually looks like.


Amazon’s SDE interview loop is the most rubric-driven in FAANG.
That sentence sounds like marketing. It is not. It means something specific.
At Amazon, interviewers do not score candidates on gut feel and write a paragraph at the end. They follow a structured rubric, score each Leadership Principle observed during their round, write specific quotes from the candidate as evidence, and submit a Hire or No-Hire recommendation that the Bar Raiser can override.
This level of structure cuts both ways for candidates. It is more predictable than a Google or Meta loop, where interviewer subjectivity carries more weight.
But it is also less forgiving.
A candidate who walks into Amazon without a story bank tagged to specific Leadership Principles, without rehearsed STAR responses with measurable outcomes, and without an understanding of how the Bar Raiser veto works will get rejected even if their coding is strong.
This post breaks down what is actually different about an Amazon loop in 2026.
Not what was true three years ago, not what generic FAANG-prep content claims. What candidates are reporting now.
What Has Stayed the Same Since 2023
Three things about Amazon’s loop are unchanged since the last big shift in 2023.
The Leadership Principles still drive everything. All 16 of them. Amazon updated the Leadership Principles in mid-2023 to add “Strive to be Earth’s Best Employer” and “Success and Scale Bring Broad Responsibility,” bringing the count to 16. The interview process was rebuilt around the new list. That structure has held.
The Bar Raiser still exists, still has veto power. The Bar Raiser is a trained interviewer from a different team than the hiring manager’s. They are explicitly tasked with maintaining or raising the engineering bar of Amazon as a whole, not optimizing for the team’s hiring needs. Their No-Hire vote cannot be overridden by enthusiasm from the rest of the panel.
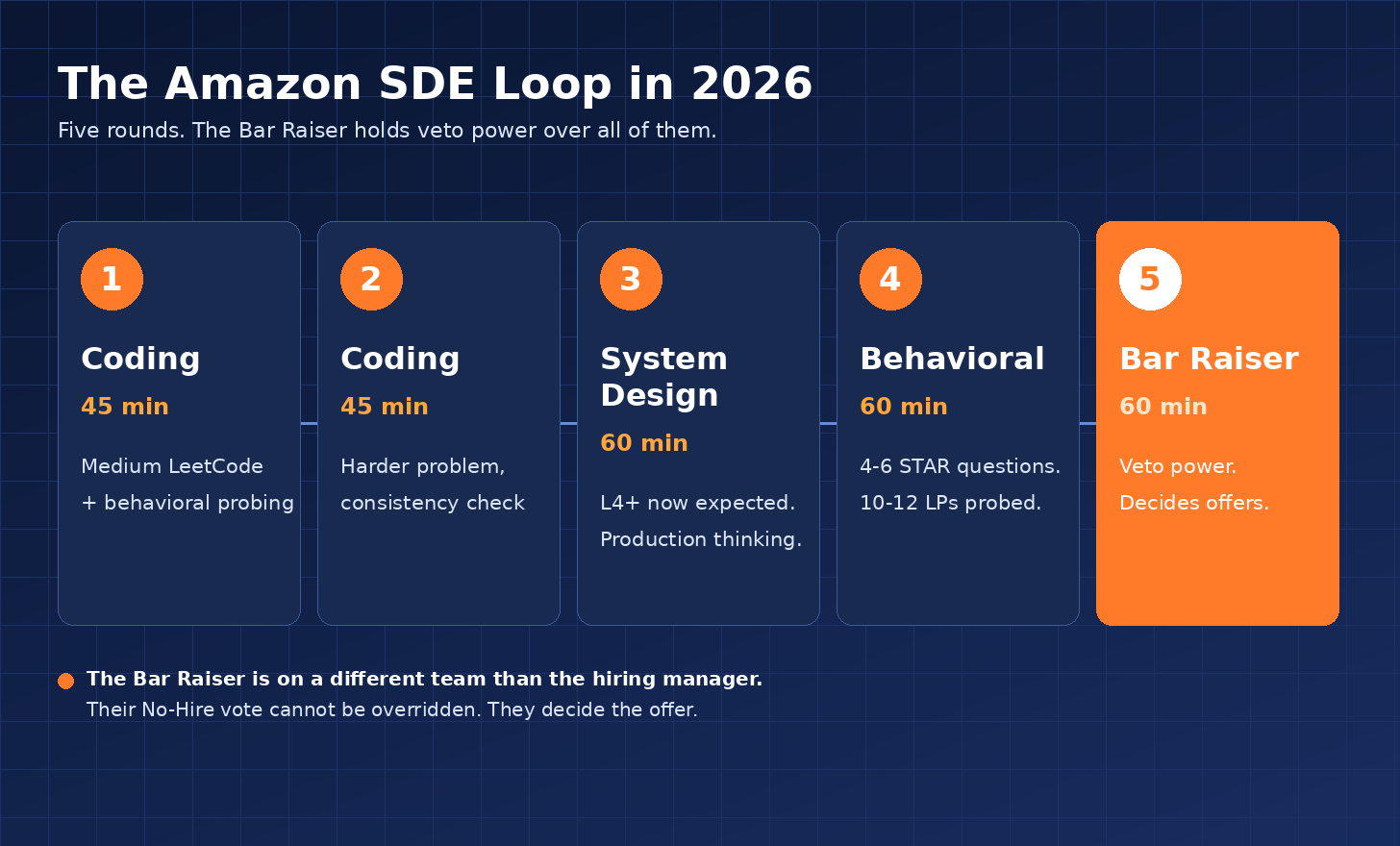
The loop is still 5 rounds for SDE candidates. Plus a recruiter screen and a phone screen before the onsite. Total time investment from the candidate’s first contact to offer is typically 4 to 8 weeks.
These foundations are stable.
What changed in 2024 and 2025 is what the rounds inside the loop now look like, what the rubric weights, and what the Bar Raiser specifically grades for.
What Changed in 2026
Three shifts that matter to anyone interviewing this year.
Shift 1: Behavioral questions appear in every round, including technical ones
This is the most underreported change.
Five years ago, behavioral and technical rounds were cleanly separated.
The behavioral round happened in a dedicated 60-minute session with a hiring manager or skip-level.
The coding rounds were coding.
The system design round was system design.
In 2026, every round contains behavioral probing.
A typical Amazon SDE coding round in 2026 looks like this: 5 minutes of introductions and behavioral warm-up, 40 to 45 minutes on the technical problem, 10 minutes of behavioral follow-up and candidate questions.
The behavioral portion is not warm-up chatter. It is being scored.
This means a candidate who treats the coding round as purely technical and saves their behavioral preparation for “the behavioral round” will score lower on the coding round itself.
Each interviewer scores the candidate on at least 2 to 4 Leadership Principles observed during their hour.
Shift 2: The Bar Raiser rubric tightened around two specific Leadership Principles
Customer Obsession and Ownership are now the two LPs Bar Raisers probe most aggressively.
This shift has been visible in candidate-reported feedback since late 2024 and has become more pronounced through 2025.
The reason this matters is mechanical: even strong candidates who have rehearsed stories for 8 of the 16 LPs sometimes have weak stories specifically for Customer Obsession and Ownership.
Coverage gaps in those two LPs are now the most common reason for Bar Raiser veto.
A candidate who has a brilliant story for Bias for Action and a brilliant story for Invent and Simplify but only generic stories for Customer Obsession is at higher risk than they were three years ago.
Shift 3: AI literacy entered the rubric
Every Amazon SDE loop in 2026 includes at least one behavioral question about AI tool usage.
The most common framing is some version of: “Tell me about a time you used or chose not to use AI tools in your engineering work.”
This is not a separate round.
It is a behavioral question that any interviewer in the loop can ask.
The Bar Raiser is more likely than not to ask it.
Hiring managers ask it frequently.
Amazon has not published a scoring guide for this question, but the pattern in candidate-reported feedback is clear.
Candidates who say they do not use AI tools score lower than candidates who describe specific use cases with explicit verification habits.
Candidates who say they use AI tools for everything also score lower than candidates who can articulate when they choose not to use them.
The interviewer is grading judgment, not enthusiasm.
The 5 Rounds, Round by Round
Here is what each round in a 2026 Amazon SDE loop actually looks like, what the interviewer is scoring, and the failure modes that quietly tank candidates.
Round 1: Coding (45 minutes)
Format: One LeetCode-style problem, typically Medium difficulty.
The candidate is expected to clarify, propose an approach, code the solution, walk through edge cases, and discuss complexity.
Standard tooling: a shared online editor (typically Amazon’s internal tool, though some interviewers use HackerRank).
What the interviewer is scoring:
Problem-solving approach: do they understand the problem before coding?
Communication: do they narrate while solving?
Code quality: is it readable and reasonably efficient?
Testing instinct: do they walk through edge cases unprompted?
Behavioral signal: at least 2 LPs observed during the hour, most commonly Earn Trust, Are Right A Lot, Deliver Results.
Top failure modes:
Solving silently. Amazon’s rubric treats this as a soft no-hire signal because Earn Trust is one of the LPs being observed.
Picking the optimal solution immediately without explaining the brute-force baseline first. This reads as rehearsed rather than thoughtful.
Skipping the test cases. The candidate codes the solution, runs the example test case provided, says “looks good,” and stops. The interviewer wanted to see edge case thinking.
What a 4-out-of-5 candidate sounds like in this round:
“Let me make sure I understand the problem first. The input is X, the output is Y, and the constraints say Z. One assumption I want to verify: when the input has duplicates, should the output preserve them or deduplicate? Got it. Let me start with a brute-force approach so we have a baseline, then optimize. The brute-force is O(n²) because... [codes brute force, runs example, identifies optimization opportunity]. The optimization here is to use a hash map for O(n) lookup, which gets us to O(n) total...”
Round 2: Coding (45 minutes, often harder)
Format: Second LeetCode-style problem, often a step harder than Round 1. Sometimes Medium-Hard or Hard.
Different interviewer than Round 1.
Why two coding rounds:
The two-coding-rounds structure exists because Amazon wants to see consistency.
A candidate who solves one Medium problem could be having a good day.
A candidate who solves two different problems with different patterns is showing reliable signal.
What is scored differently in Round 2:
The technical bar is higher.
Round 1 forgives some inefficiency.
Round 2 expects the candidate to recognize the pattern faster and code more cleanly. Behavioral scoring continues but is typically lighter than Round 1, with the interviewer assuming the candidate has settled in.
Top failure modes:
Treating Round 2 like Round 1. Some candidates pace their performance for one coding round and run out of mental energy halfway through the second. The Round 2 interviewer is comparing the candidate to other candidates’ Round 2 performance, not their own Round 1.
Recycling the exact same communication patterns from Round 1. Candidates who say the exact same opening lines in both rounds (because they rehearsed) sometimes get a “felt rehearsed” note in the debrief.
Round 3: System Design (60 minutes)
Format: Open-ended system design question. For SDE II (L5), this is now standard. For SDE I (L4), system design has appeared in approximately 60 to 70 percent of recent loops, up from 20 to 30 percent in 2023.
SDE III (L6) and above always get system design, often two rounds.
What the interviewer is scoring:
Problem framing: do they ask clarifying questions before drawing?
High-level architecture: can they decompose into components?
Specific component depth: when asked “how does the cache layer work,” can they go three layers deep?
Trade-off articulation: do they explicitly name what they’re trading and why?
Production thinking: do they consider failure modes, observability, deployment?
Top failure modes:
Drawing too fast. Candidates who start drawing within the first 90 seconds usually have not understood the problem. The interviewer is grading scope discipline.
Refusing to commit to a choice. When the interviewer asks “would you use SQL or NoSQL here,” candidates who answer “it depends on requirements” without then committing to one for this specific problem score lower than candidates who say “for this use case I’d use Postgres because of the relational query patterns, here’s why.”
Skipping production concerns. A design that works in the happy path but never addresses how the system handles a failed dependency, a slow database, or a deployment rollback gets a 3 out of 5 even if the architecture is otherwise sound.
What is being graded that candidates don’t realize:
Bar Raisers in 2026 specifically probe for two things during system design: whether the candidate considered cost (because Amazon engineering is cost-aware to a degree most companies are not), and whether the candidate considered observability and operational pain (because Amazon has the most production-incident-aware engineering culture in big tech).
A system design answer that does not mention monitoring, alerting, or how the on-call engineer would debug a problem is reading as immature regardless of the architectural correctness.
Round 4: Behavioral / Leadership Principles Deep Dive (60 minutes)
Format: Dedicated behavioral round, typically with the hiring manager or a senior engineer.
Interviewer asks 4 to 6 STAR questions, each tagged to one or two specific Leadership Principles. Follow-up questions probe for specificity and ownership detail.
Structure of a typical question and follow-up:
The interviewer asks: “Tell me about a time you had to make a difficult decision with incomplete information.”
The candidate gives a 2-to-3-minute STAR answer.
The interviewer follows up with three layers of specificity probes:
“What was the actual data you had?”
“Who else was involved in that decision?”
“What would you do differently?”
Most candidates have prepared the surface story but not the layers.
The follow-ups are where the round is actually decided.
LP coverage in this round:
The hiring manager and Bar Raiser coordinate before the loop on which LPs each interviewer will probe.
Round 4 typically covers 4 to 6 LPs.
Combined with the LPs probed in the technical rounds, the loop covers 10 to 12 of the 16 LPs total.
The remaining 4 to 6 are either covered by the candidate’s resume materials or assumed.
This is why preparation has to cover the full LP list, not the 4 most popular ones. You don’t know in advance which ones will be probed.
Top failure modes:
Stories with no measurable outcome. “We improved the customer experience” without a number is treated as a non-answer. The Bar Raiser writes “no measurable outcome” in the debrief and the round is effectively neutral.
Stories where the candidate disappears from the action. Behavioral answers that say “we” for every action and never specify what the candidate personally did read as deflection.
Stories that match too cleanly to one LP. “I demonstrated Customer Obsession by...” sounds rehearsed and triggers skepticism. Strong stories let the LP emerge from the events, not get announced.
Round 5: Bar Raiser (60 minutes)
Format: This is the most variable round in format. Some Bar Raisers do a hybrid technical-and-behavioral round. Some do pure behavioral. Some do a system design with heavy LP probing.
The candidate is usually not told which interviewer is the Bar Raiser.
Sometimes it’s obvious (the most senior person, asking the most pointed follow-ups).
Often it’s not.
What the Bar Raiser specifically grades:
The Bar Raiser is asking themselves a different question than the other interviewers.
The hiring manager is asking “would I want to hire this person.”
The Bar Raiser is asking “would hiring this person raise or lower the bar of Amazon as a whole.”
This is why a candidate can get four “Hire” votes and still be rejected.
The Bar Raiser concluded that the candidate would be net-neutral or net-negative on the Amazon-wide bar at this level. Their veto is final.
The 2026 Bar Raiser tightening:
As mentioned earlier, Customer Obsession and Ownership coverage is now the most common veto trigger.
Bar Raisers also probe more aggressively on the AI literacy question and on how the candidate would handle a specific scenario where engineering excellence and customer outcome conflict.
Top failure modes specific to the Bar Raiser round:
Giving the same stories already given in Round 4. The Bar Raiser has read the Round 4 debrief notes before the round starts and is specifically looking for new stories or deeper layers on existing ones.
Performing for the Bar Raiser differently than for other interviewers. The Bar Raiser is trained to notice when a candidate is calibrating their answers based on perceived seniority of the interviewer. This itself reads as inauthentic and gets noted.
Failing to ask substantive questions at the end. The Bar Raiser is one of the few interviewers who treats “do you have questions for me” as a real evaluative moment. Generic questions about culture or growth get a polite answer and no rubric note. Specific questions about engineering practices, recent customer incidents, or the team’s stance on technical debt get noted as positive signal.
How the Debrief Actually Works
After all five rounds, the panel meets for a debrief, typically 60 to 90 minutes. This is where the offer decision is made.
Each interviewer reads their notes aloud. They state their Hire / No Hire vote and the LPs they observed. They include direct quotes from the candidate as evidence.
The Bar Raiser typically goes last.
If the panel is unanimous, the decision is fast.
Unanimous Hire goes to offer.
Unanimous No Hire goes to rejection.
Most candidates fall in between.
The interesting decisions happen on mixed votes.
The hiring manager wants to hire. One round was a No Hire.
The Bar Raiser is leaning toward No Hire.
This is where the conversation gets specific.
The hiring manager has to defend why the No-Hire round was an outlier.
The Bar Raiser has to articulate what specifically does not meet the bar.
If the Bar Raiser holds firm on No Hire, the candidate is rejected.
If the Bar Raiser is convinced, the candidate gets an offer at potentially a downleveled position (SDE II offer instead of SDE III, or SDE I offer instead of SDE II).
What This Means for How You Prepare
If you have an Amazon loop scheduled in the next 60 to 90 days, here is what to do this week, in order of priority.
Build your 8-story bank, not your 5-story bank
The classic Amazon prep advice is “five stories.” That advice is undercalibrated for 2026.
Five stories cannot cover 16 LPs with any depth.
Build 8 to 10 stories.
Each story should be tagged to 2 to 4 LPs. Aim for total coverage of all 16 LPs across the bank, with at least two strong stories each for Customer Obsession, Ownership, Bias for Action, and Earn Trust (the four most-probed LPs in 2026).
For each story, prepare three layers: a 60-second version, a 3-minute STAR version, and a 5-minute deep version with follow-up answers.
Practice the deep version most.
The follow-ups are where rounds are decided.
Pressure-test your stories against the specificity probes
For each story, write down the answers to:
“What was the actual number?”
“Who specifically was involved?”
“What would you do differently?”
“What did you learn?”
If you cannot answer all four for any story, that story is not ready.
Practice the AI literacy answer specifically
This is now in every loop.
Have one prepared answer that includes: a specific use case where you used AI well, a specific use case where you chose not to use it (and why), a specific verification habit you have, and a specific limitation you’ve encountered.
The answer should be 90 seconds maximum.
Longer answers come across as monologuing.
Pressure-test your “we” to “I” ratio
Read your stories out loud.
Count the “we” mentions versus the “I” mentions.
If “we” outnumbers “I” by more than 2:1 in any story, the story will read as deflection to the Bar Raiser.
Rewrite it with “I” claiming the actions you actually took, paired with appropriate “we” for context about the team.
Have substantive questions ready for the Bar Raiser
Prepare 3 to 5 questions that demonstrate engineering judgment.
Examples that work:
“What’s the most painful production incident this team has had in the last year and what changed because of it?”
“How does the team make trade-offs between feature velocity and technical debt?”
“What’s the operational on-call experience like for this service?”
Generic questions about culture, growth, or what you’ll be doing don’t get rubric notes.
The Bar Raiser is grading your engineering taste through the questions you ask.
A Note on Downleveling
Amazon downlevels more aggressively than other FAANG companies.
A candidate interviewing for SDE III who performs at “good but not exceptional” will frequently get an SDE II offer instead of being rejected.
This is technically a positive outcome, but it surprises candidates who expected pass-or-fail.
If you walk into an SDE III loop and your story bank does not show clear L6-level scope (multi-team impact, owning architecture decisions across services, mentoring other engineers visibly), you will likely be downleveled even if your coding is strong.
The signal that gets you the level you actually want, not a downlevel, is depth on Ownership and Deliver Results paired with examples of cross-team impact.
Stories that show you owned outcomes that other teams depended on.
Stories where you mentored or unblocked others.
If you want SDE III specifically, your story bank needs at least two stories that demonstrate this kind of scope.
Without them, the panel will conclude SDE II and the offer comes back at that level.
Final Word
Amazon’s loop is structured.
That structure is its failure mode for unprepared candidates and its opportunity for prepared ones.
A candidate who shows up with a tight 8-story bank, with all 16 LPs covered, with measurable outcomes in every story, with the AI literacy answer rehearsed, and with specific questions for the Bar Raiser is in the top 20 percent of candidates the panel will see this quarter.
That is not because the bar is low.
It is because most candidates do not prepare at this level of structure. They prepare topics. They do not prepare for the rubric.
The candidates who get offers are the ones who treat the rubric as the test it actually is.